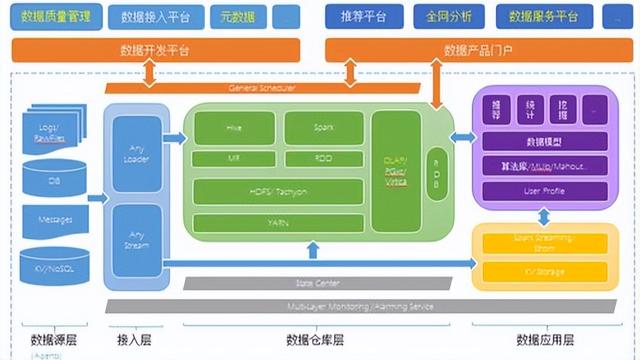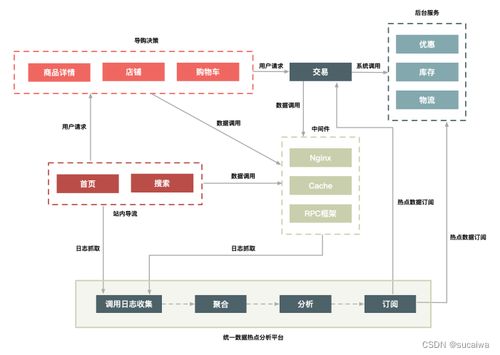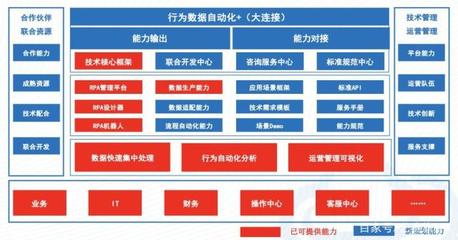
在当今的数据密集型应用中,缓存技术已成为提升系统性能、降低数据库负载的关键手段。缓存与数据库之间的一致性问题,却是数据处理服务中一个复杂且常见的挑战。当数据在缓存和数据库中出现不一致时,可能导致用户看到过时、错误的信息,进而影响业务逻辑的正确性和用户体验。
一致性问题的主要根源
缓存与数据库不一致的根本原因在于两者是独立的存储系统,且数据更新操作通常无法在单个原子事务中完成。主要场景包括:
- 更新顺序与并发:在高并发场景下,对同一数据的“读”和“写”操作可能以难以预测的顺序交织进行。例如,先更新数据库成功,但更新缓存失败或延迟,后续的读请求可能仍从缓存中获取到旧数据。
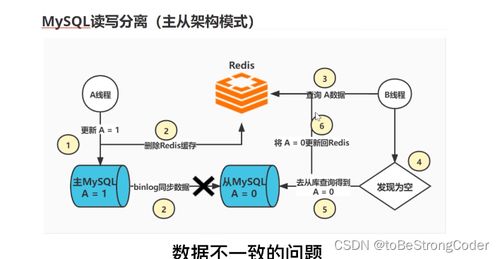
- 缓存失效策略:常用的策略如“先更新数据库,再删除缓存”(Cache-Aside 或 Lazy Loading)并非万无一失。在极端并发下,一个线程在更新数据库后、删除缓存前,另一个线程可能读取了旧的数据库值并重新加载到缓存中,导致缓存被“污染”为旧值。
- 数据同步延迟:在分布式系统中,数据库主从复制存在延迟。如果应用从从库读取数据并写入缓存,而主库的更新尚未同步到从库,缓存中就会存入旧数据。
- 复杂的业务逻辑:一个业务操作可能涉及多个数据实体的更新,确保所有这些更新在缓存和数据库中都保持原子性和一致性非常困难。
对数据处理服务的影响
对于专门的数据处理服务(如ETL管道、实时计算引擎、API服务层),不一致性问题会带来直接冲击:
- 计算准确性受损:如果服务依赖于缓存数据进行分析、聚合或业务规则判断,脏数据会导致计算结果错误。
- 服务可靠性下降:不一致可能表现为间歇性的数据错误,难以排查和复现,降低了服务的SLA(服务水平协议)。
- 系统复杂性增加:为了缓解一致性问题,往往需要在服务代码中引入复杂的同步逻辑、重试机制或补偿事务,增加了开发和维护成本。
主流解决方案与实践
没有“银弹”能解决所有一致性问题,通常需要根据业务对一致性、性能和复杂度的要求进行权衡和选择。
- 合理设置缓存过期时间(TTL):为缓存数据设置一个较短的生存时间,强制定期从数据库刷新。这是一种最终一致性方案,简单有效,适用于对一致性要求不非常严格的场景(如热点新闻、商品描述)。
- 优化缓存更新策略:
- Cache-Aside(旁路缓存):应用代码显式管理缓存。读时未命中则从数据库加载;写时先更新数据库,然后删除(而非更新)缓存。这是最常用的模式,但需注意前述的并发漏洞。
- Write-Through(直写):写操作同时更新缓存和数据库(通常在缓存层中实现)。这保证了强一致性,但所有写操作都承受数据库的延迟,性能有损耗。
- Write-Behind(后写):写操作只更新缓存,再由缓存异步批量写入数据库。性能极高,但存在数据丢失风险(缓存崩溃),一致性最弱。
- 引入分布式锁或队列:对于关键数据,在更新时使用分布式锁,确保“读-更新数据库-删缓存”这一序列操作的原子性,防止并发干扰。更复杂的方案可以将数据库更新和缓存操作通过消息队列串行化处理。
- 采用数据库变更日志捕获(CDC):使用如Debezium、Canal等工具监听数据库的Binlog或WAL,将数据变更事件发布到消息队列。然后由一个独立的缓存维护服务消费这些事件,来更新或失效缓存。这实现了缓存与数据库的准实时解耦同步,一致性高,对业务代码侵入小。
- 容忍延迟与版本控制:对于某些场景,可以接受短暂的不一致。可以为数据增加版本号或时间戳,客户端或服务端在发现数据版本过旧时,可以触发一次刷新或提示用户。
给数据处理服务的设计建议
- 评估一致性需求:明确业务对数据一致性的真实要求(强一致、最终一致、会话一致),避免过度设计。
- 缓存分层与降级:区分核心业务数据(高一致性要求)和辅助数据(可接受延迟),采用不同的缓存策略。确保在缓存系统故障时,服务能优雅降级至直接访问数据库。
- 监控与告警:建立完善的监控,追踪缓存命中率、数据库与缓存的数据差异(如通过定期抽样对比),并设置告警。
- 标准化与封装:在数据处理服务框架中,将缓存访问逻辑(包括读写、失效策略、异常处理)封装成统一的组件或中间件,减少业务代码中的重复和错误。
缓存与数据库的一致性是数据处理服务架构中必须慎重对待的问题。通过深入理解问题根源,结合业务场景选择合适的策略组合,并辅以良好的设计、监控和运维,才能在享受缓存带来的性能红利的将数据不一致的风险控制在可接受的范围内。